Causal inference
Causal inference is a key concept in statistics and machine learning, focusing on determining cause-effect relationships between variables. It involves understanding the causal effect, which is the change in one variable (effect) due to a change in another variable (cause), while keeping all other variables constant. This process also considers counterfactuals, hypothetical scenarios that represent what could have happened under different circumstances. Confounding variables, which influence both the cause and effect, are also a crucial part of causal inference as they can lead to misleading associations.
Causal inference uses causal graphs and mathematical models to represent and understand these relationships. However, establishing these relationships is challenging because correlation does not imply causation, and the true causal effect often requires randomized controlled experiments, which may not always be feasible or ethical. Therefore, various methods for causal inference from observational data have been developed. In machine learning, understanding these cause-effect relationships is essential, especially in fields like healthcare, economics, and social sciences, where they can inform effective interventions and policies.
Adaptive transfer
- Vo, T. V., Bhattacharyya, A., Lee, Y., & Leong, T. Y. (2022). An Adaptive Kernel Approach to Federated Learning of Heterogeneous Causal Effects. Advances in Neural Information Processing Systems, 35, 24459-24473. https://proceedings.neurips.cc/paper_files/paper/2022/file/9a9afa70eead1805f00e3a0df2a41157-Paper-Conference.pdf
![]()
We introduce an adaptive transfer algorithm that learns the similarities among multiple, decentralized data sources by utilizing Random Fourier Features. This method allows us to disentangle the loss function into multiple components, each associated with a data source. The data sources may have different distributions, and we independently and systematically incorporate the causal effects.
Our proposed method estimates the similarities among the sources through transfer coefficients, requiring no prior information about the similarity measures. The heterogeneous causal effects can be estimated without sharing the raw training data among the sources, thus minimizing the risk of privacy leak.
We also provide minimax lower bounds to assess the quality of the parameters learned from the disparate sources. Our proposed method is empirically shown to outperform the baselines on decentralized data sources with dissimilar distributions.
Approach
Our central task to estimate the Conditional Average Treatment Effect (CATE) and Average Treatment Effect (ATE) is to find the expectation of the outcome Y under an intervention on W of an individual in source s. With the existence of the latent confounder Z, we can further expand this quantity using do-calculus. In particular, from the backdoor adjustment formula, we calculate the expectation of the outcome Y under an intervention on W of an individual in source s as the integral of the expectation of Y given W and Z times the conditional probability of Z given X over all possible values of Z.
The data sources may have different distributions, and we independently and systematically incorporate the causal effects. Our proposed method estimates the similarities among the sources through transfer coefficients, requiring no prior information about the similarity measures. We estimate the heterogeneous causal effects without sharing the raw training data among the sources, thus minimizing the risk of privacy leak.
In practice, if the assumption that each individual appears in at most one source does not hold, we perform a pre-training step to exclude such duplicated individuals. This step uses a one-way hash function to perform a secured matching procedure that identifies duplicated individuals.
We also provide minimax lower bounds to assess the quality of the parameters learned from the disparate sources. Our proposed method is empirically shown to outperform the baselines on decentralized data sources with dissimilar distributions.
Boosting Transfer Learning
- He, Jiancong, et al. "Boosting transfer learning improves performance of driving drowsiness classification using EEG." 2018 International Workshop on Pattern Recognition in Neuroimaging (PRNI). IEEE, 2018.
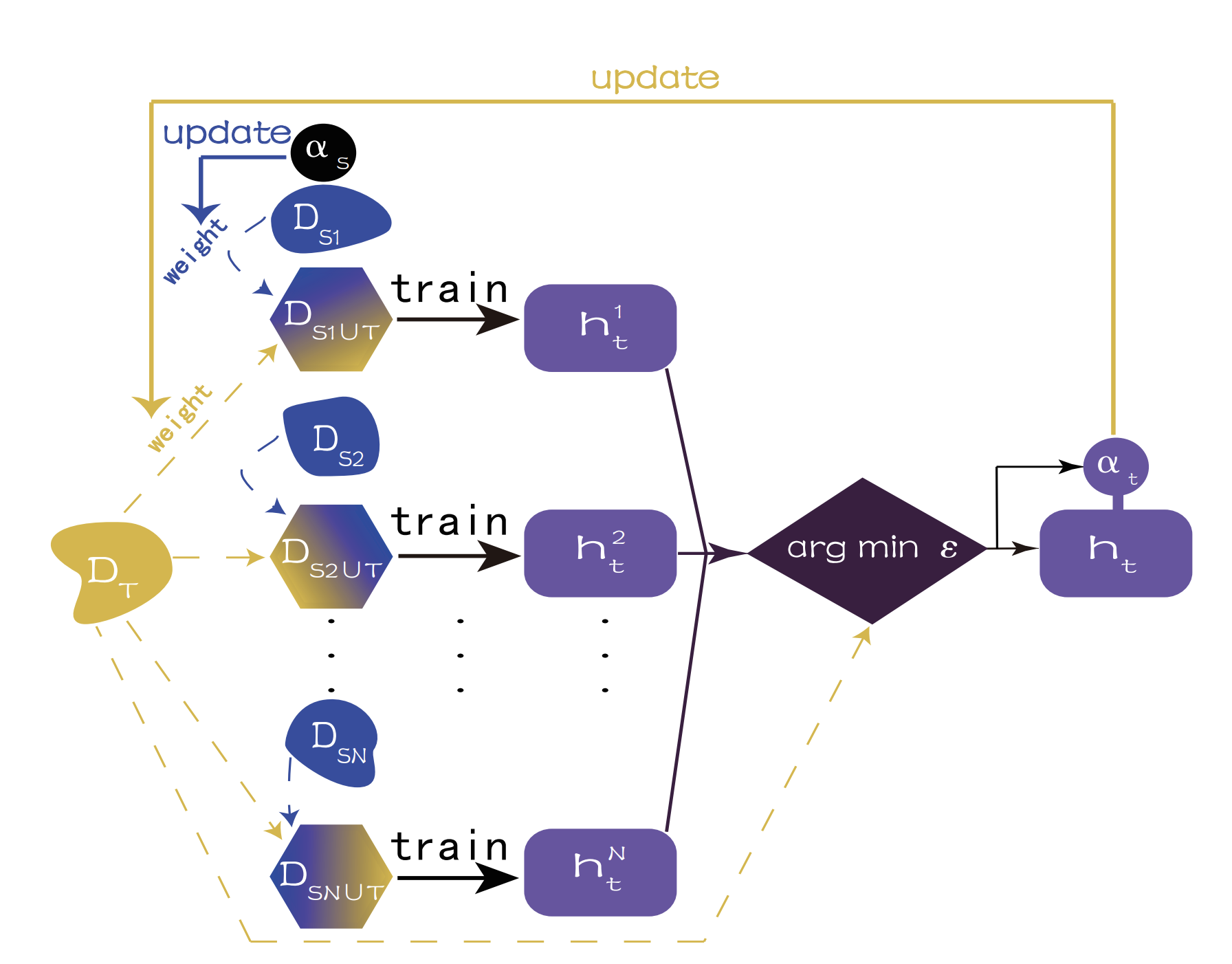
The paper presents a study that aims to improve the performance of driving drowsiness classification using EEG signals. The authors propose a method that combines a boosting strategy and transfer learning to identify driving drowsiness states from alertness states based on the features of power spectral density (PSD). The model, trained using data collected a few days prior, is tuned using a small portion of the data collected in the current session. The results demonstrate that the proposed boosting transfer learning method significantly outperforms the support vector machine (SVM) and AdaBoost methods. The authors suggest that this method could promote practical use of drowsiness detection systems in real vehicles due to its good cross-session performance.
Approach
The method involves combining a boosting strategy and transfer learning to establish a model for identifying driving drowsiness states from alertness states based on the features of power spectral density (PSD). The model is trained using data collected a few days prior (considered as the source session) and is tuned using a very small portion of the data collected in the current session (considered as the target session). The authors use a strategy known as MultiSourceTrAdaBoost, where samples from the source session are randomly partitioned into multiple groups, which are considered as multiple sources. This helps reduce the risk of negative transfer. The model’s performance is then tested in the current session. The results show that the proposed boosting transfer learning method significantly outperforms the SVM and AdaBoost methods.